





How to make a winning portfolio with the epic Black-Litterman approach
In today's newsletter, we're going to dive deep into the Black-Litterman model.
This powerful tool, used by professional investors worldwide, combines personal views on asset performance with historical market data to create a personalized asset allocation strategy.
By the end of this issue, you'll have the Python code and understanding to use the Black-Litterman model just like the pros.
Let's get started!
How to make a winning portfolio with the epic Black-Litterman approach
The Black-Litterman model is a mathematical tool for portfolio allocation. It was developed in 1990 by Fischer Black and Robert Litterman at Goldman Sachs.
The Black-Litterman model takes a Bayesian approach to asset allocation. Specifically, it combines a prior estimate of returns with views on certain assets, to produce a posterior estimate of expected returns.
It starts with an asset allocation based on the equilibrium assumption, which suggests that assets will perform in the future as they have in the past. The model then modifies this initial allocation by considering the investor's views on future asset performance.
Black-Litterman incorporates subjective views into market equilibrium returns providing a more personalized approach to asset allocation.
Here's how to do it with Python.
Imports and set up
We'll use PyPortfolioOpt to construct the Black-Litterman portfolio weights. We'll also use the OpenBB SDK for data and seaborn for plotting.
Set up the Black-Litterman model
The Black-Litterman model supports absolute or relative views. Absolute views are statements like: \"AAPL will return 20%\" or \"BBY will drop 40%\". Relative views, on the other hand, are statements like \"GOOG will outperform FB by 3%.\"
This issue covers absolute views.
These views are passed to PyPortfolioOpt in the form of a Python dictionary. Each symbol is mapped to an absolute return. Then, we create a sample covariance matrix.
Finally, we're ready to set up the Black-Litterman model.
The pi argument is the estimate of the priors. You can think of the prior as the \"default\" estimate, in the absence of any information. Black and Litterman provide the insight that a natural choice for this prior is the market's estimate of the return, which is embedded into the market capitalization of the asset.
We can use whatever priors we want. PyPortfolioOpt has a built in option equal-weighted priors, so we'll use that.
From there, we generate the returns and build an efficient frontier using the default return optimization.
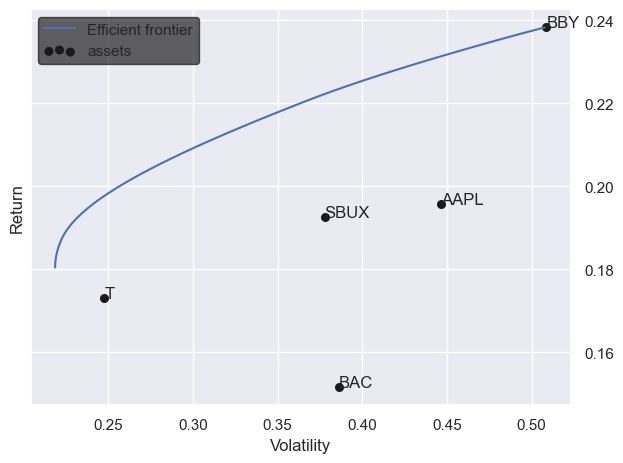
PyPortfolioOpt generates the efficient frontier which minimizes volatility and maximizes return using the Black-Litterman asset weights.
Next steps
There are two action steps you can take.
The first is to experiment with different priors. You can use anything that you want.
The second is to form relative views (instead of just absolute views). This type of view is useful when considering a relative return portfolio of managing an active trading strategy that seeks to beat a benchmark.