How To Compute Volatility 6 Ways Most People Don’t Know






How To Compute Volatility 6 Ways Most People Don’t Know
How To Compute Volatility 6 Ways Most People Don’t Know
In today’s issue, I’m going to show you 6 ways to compute statistical volatility in Python.
The first way you've probably heard of. The other 5 may be new to you.
Statistical volatility (also called historic or realized volatility) is a measurement of how much the price or returns of stock value. It’s used to optimize portfolios, detect regime changes, and price derivatives. The most common way to measure statistical volatility is the standard deviation.
Unfortunately, there are some downsides to using standard deviation that most people don’t consider.
Before I show you how to compute volatility in 6 different ways, let's get setup.
Jupyter Notebook
I recommend using Jupyter Notebook. Jupyter Notebook is free and can be installed with pip:
1pip install notebookStock Price Data
First, we’ll use the excellent yFinance library to grab some stock price data. We’ll also import the math and NumPy libraries.
1import math
2
3import numpy as np
4import yfinance as yf
5
6
7data = yf.download("AAPL", start="2017-01-01", end="2022-06-30")One line of code and we have four years of AAPL data. What a great time to be alive.
A quick plot of the daily close shows us the price chart of Apple.
1data['Close'].plot()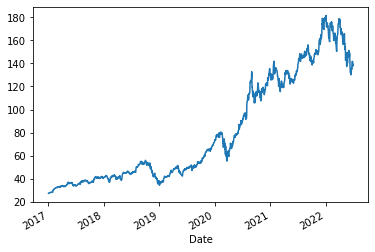
Standard Deviation
We'll start with the standard deviation. Standard deviation measures how widely returns are dispersed from the average return. It’s the most common (and biased) estimator of volatility.
1def standard_deviation(price_data, window=30, trading_periods=252, clean=True):
2
3 log_return = (price_data["Close"] / price_data["Close"].shift(1)).apply(np.log)
4
5 result = log_return.rolling(window=window, center=False).std() * math.sqrt(
6 trading_periods
7 )
8
9 if clean:
10 return result.dropna()
11 else:
12 return resultLet's plot it:
1standard_deviation(data).plot()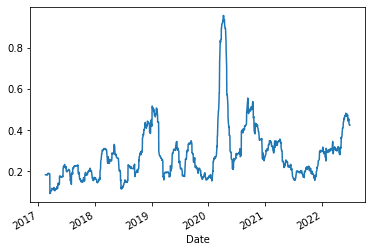
Parkinson
Parkinson's volatility uses the stock’s high and low price of the day rather than just close to close prices. It’s useful to capture large price movements during the day.
1def parkinson(price_data, window=30, trading_periods=252, clean=True):
2
3 rs = (1.0 / (4.0 * math.log(2.0))) * (
4 (price_data["High"] / price_data["Low"]).apply(np.log)
5 ) ** 2.0
6
7 def f(v):
8 return (trading_periods * v.mean()) ** 0.5
9
10 result = rs.rolling(window=window, center=False).apply(func=f)
11
12 if clean:
13 return result.dropna()
14 else:
15 return resultWe take the price data and compute a 30-day rolling volatility metric that we can plot.
parkinson(data).plot()

Garman-Klass
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
1def garman_klass(price_data, window=30, trading_periods=252, clean=True):
2
3 log_hl = (price_data["High"] / price_data["Low"]).apply(np.log)
4 log_co = (price_data["Close"] / price_data["Open"]).apply(np.log)
5
6 rs = 0.5 * log_hl ** 2 - (2 * math.log(2) - 1) * log_co ** 2
7
8 def f(v):
9 return (trading_periods * v.mean()) ** 0.5
10
11 result = rs.rolling(window=window, center=False).apply(func=f)
12
13 if clean:
14 return result.dropna()
15 else:
16 return resultLet’s plot it:
1garman_klass(data).plot()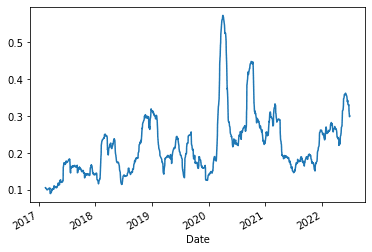
Hodges-Tompkins
Hodges-Tompkins volatility is a bias correction for estimation using an overlapping data sample that produces unbiased estimates and a substantial gain in efficiency.
1def hodges_tompkins(price_data, window=30, trading_periods=252, clean=True):
2
3 log_return = (price_data["Close"] / price_data["Close"].shift(1)).apply(np.log)
4
5 vol = log_return.rolling(window=window, center=False).std() * math.sqrt(
6 trading_periods
7 )
8
9 h = window
10 n = (log_return.count() - h) + 1
11
12 adj_factor = 1.0 / (1.0 - (h / n) + ((h ** 2 - 1) / (3 * n ** 2)))
13
14 result = vol * adj_factor
15
16 if clean:
17 return result.dropna()
18 else:
19 returnLet’s plot it:
1hodges_tompkins(data).plot()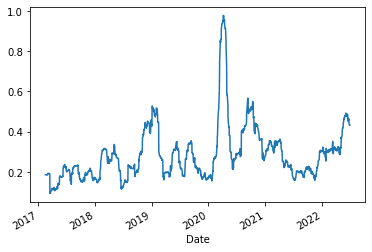
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero. Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates a drift term (mean return not equal to zero).
1def rogers_satchell(price_data, window=30, trading_periods=252, clean=True):
2
3 log_ho = (price_data["High"] / price_data["Open"]).apply(np.log)
4 log_lo = (price_data["Low"] / price_data["Open"]).apply(np.log)
5 log_co = (price_data["Close"] / price_data["Open"]).apply(np.log)
6
7 rs = log_ho * (log_ho - log_co) + log_lo * (log_lo - log_co)
8
9 def f(v):
10 return (trading_periods * v.mean()) ** 0.5
11
12 result = rs.rolling(window=window, center=False).apply(func=f)
13
14 if clean:
15 return result.dropna()
16 else:
17 return resultLet's plot it:
1rogers_satchell(data).plot()
Yang-Zhang
Yang-Zhang volatility is the combination of the overnight (close-to-open volatility), a weighted average of the Rogers-Satchell volatility and the day's open-to-close volatility.
1def yang_zhang(price_data, window=30, trading_periods=252, clean=True):
2
3 log_ho = (price_data["High"] / price_data["Open"]).apply(np.log)
4 log_lo = (price_data["Low"] / price_data["Open"]).apply(np.log)
5 log_co = (price_data["Close"] / price_data["Open"]).apply(np.log)
6
7 log_oc = (price_data["Open"] / price_data["Close"].shift(1)).apply(np.log)
8 log_oc_sq = log_oc ** 2
9
10 log_cc = (price_data["Close"] / price_data["Close"].shift(1)).apply(np.log)
11 log_cc_sq = log_cc ** 2
12
13 rs = log_ho * (log_ho - log_co) + log_lo * (log_lo - log_co)
14
15 close_vol = log_cc_sq.rolling(window=window, center=False).sum() * (
16 1.0 / (window - 1.0)
17 )
18 open_vol = log_oc_sq.rolling(window=window, center=False).sum() * (
19 1.0 / (window - 1.0)
20 )
21 window_rs = rs.rolling(window=window, center=False).sum() * (1.0 / (window - 1.0))
22
23 k = 0.34 / (1.34 + (window + 1) / (window - 1))
24 result = (open_vol + k * close_vol + (1 - k) * window_rs).apply(
25 np.sqrt
26 ) * math.sqrt(trading_periods)
27
28 if clean:
29 return result.dropna()
30 else:
31 return resultLet's plot it:
1yang_zhang(data).plot()
Which One Do I Use?
Each measure has tradeoffs you must consider. Most practitioners will choose the one they believe captures the information they think is relevant. In a future issue, I’ll show you how to build a simple trading strategy based on different volatility measures.
