
Datasets, DataLoaders and PyTorch’s New DataPipes
PyTorch is an open source machine learning framework. It enables fast and efficient production through easy front-end training. It also has an ecosystem of tools and libraries.
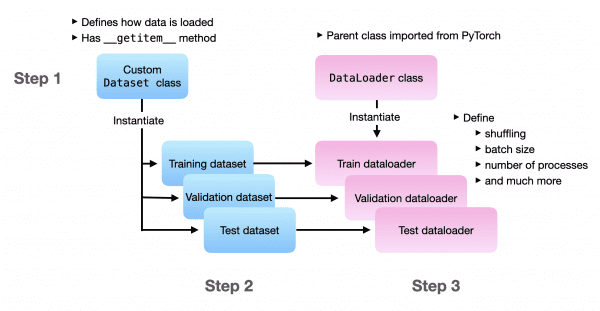
The PyTorch team recently launched TorchData. TorchData is a prototype library of common data loading utilities. It’s useful for constructing flexible pipelines. TorchData focuses on DataPipes. These DataPipes are going to replace the DataLoader for PyTorch’s current DataSet.
What does this DataLoader do?
DataLoader is helpful in getting the next minibatch ready as soon as the model is ready.
Now, you might be wondering why PyTorch’s existing DataLoader needs replacement. It’s because the DataLoader currently has a complex logic to do many things.
So, one goal of PyTorch’s new DataPipes is to simplify the DataLoader. The new DataPipes will also provide components for building Datasets in an easy way. This is because users make use of the Dataset class together with the DataLoader.
Combining DataPipes with the present DataLoader is the main way of using them. But the team aims to keep the original Dataset and DataLoader. This will help users so that they don’t have to worry about adapting to the new DataPipes immediately.
Read more at sebastianraschka.com.